Проектирование современного DWH: слои, модели и SQL-реализации
Зачем нужно DWH
- Повышать качество данных. Система интегрирует, очищает и нормализует данные из разных источников. Вы избегаете дублей, ошибок и несоответствий в информации.
- Принимать обоснованные управленческие решения. DWH предоставляет доступ к актуальной и исторической информации. А аналитические инструменты помогают глубоко анализировать данные и выявлять скрытые закономерности.
- Повышать эффективность работы. Система автоматизирует сбор, обработку и анализ данных. Это особенно актуально в крупных компаниях с большими объемами информации.
- Объединять данные. DWH собирает информацию из различных источников в единую систему, чтобы было проще управлять и анализировать ее. Это важно компаниям с разветвленной структурой и множеством подразделений.
- Видеть изменения. Система сохраняет историю, что позволяет анализировать изменения и отслеживать долгосрочные тенденции.
- Наращивать производительность. DWH нужно для быстрого выполнения сложных аналитических запросов и обработки больших объемов данных.
- В торговле: анализируйте продажи, поведение клиентов, эффективность рекламных кампаний, прогнозируйте спрос и управляйте запасами.
- В финансовом секторе: анализируйте риски на основании исторических данных, прогнозируйте финансовые показатели, выявляйте случаи мошенничества.
- В здравоохранении: повышайте качество диагностики и лечения, оптимизируйте использование оборудования, следите за эффективностью разных методик.
- В производстве: отслеживайте эффективность производственных линий, анализируйте вероятность и причины брака, оптимизируйте запасы на основе прошлых показателей.
- Представьте, что у вас сеть магазинов. Вам нужно:
- понимать, какие товары продаются лучше;
- понимать поведение клиентов;
- прогнозировать спрос;
- оптимизировать запасы.
- Чтобы сделать это, вы анализируете данные: заказы, отзывы, остатки товаров на складе. Но каждый источник сведений — как человек, говорящий на своем языке. Вам же нужно заставить всех общаться в одном пространстве. Здесь и рождается DWH — переводчик и организатор этого многоязычия. Без системы вы будете как капитан корабля без карты: наверняка доплывете до берега, но не факт, что до того, который нужен.
- интеграция данных — информация из разных источников объединяется и хранится в едином формате;
- временная ориентация — исторические данные хранятся, чтобы можно было анализировать изменения;
- предметная ориентация — данные структурируются по бизнес-направлениям.

Павел Лукьянов
Заместитель CTO AGIMA
Архитектура DWH
- Источники данных — система собирает первичную информацию из веб-сайтов, биллинговых, CRM- и ERP-систем, а заодно из баз данных компании, например, рекламных кабинетов и файлов Excel.
- Хранилище данных — система структурирует поступившую информацию, приводит данные к единому формату и обрабатывает их.
- Витрина данных — система преобразует данные в удобную для анализа форму.
- Обслуживающие системы — система смотрит состояние данных, устраняет ошибки, собирает и анализирует логи.
- BI-интерфейс — система анализирует данные, приводит их к понятному виду, создает дашборды и графики. На выходе специалисты получают готовые отчеты.
- опорная зона (Data Staging Area) — временное хранилище для загрузки первичной информации из разных источников;
- хранилище (Data Warehouse) — основное хранилище очищенных и структурированных данных в удобной для анализа форме;
- ETL/ELT-система — инструменты для извлечения, преобразования и загрузки данных в хранилище;
- система управления — инструменты администрирования, мониторинга и обеспечения безопасности данных;
- инструменты доступа — средства для работы с данными, например, BI-системы и отчеты.
- Раздел «Ваши траты за месяц» в приложении банка — это результат работы всех слоев. Сырые транзакции (ODS) превратились в очищенные операции (DDS), а затем — в красивый отчет (CDM).
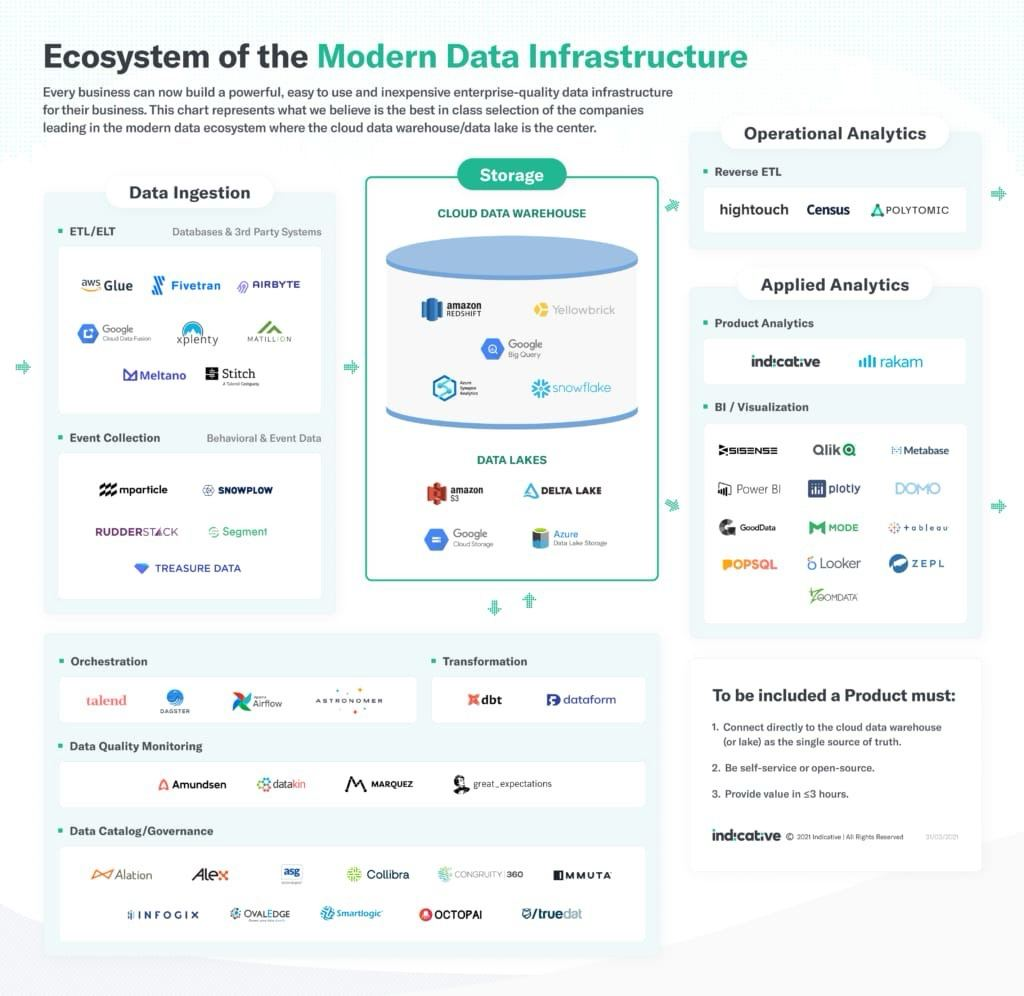
- СУБД — специализированные решения (Snowflake) или популярные базы данных (PostgreSQL, ClickHouse);
- ETL-инструменты — готовые решения (Informatica, Talend) или собственные разработки;
- инструменты аналитики — BI-платформы (Power BI, Metabase и Superset) или кастомные решения.
- гибко масштабировать ресурсы;
- снижать затраты на IT-инфраструктуру;
- обеспечивать высокую надежность работы;
- интегрировать различные сервисы без дополнительного кодирования.
Слойная структура хранилища
Павел Лукьянов
Заместитель CTO AGIMA
- RDBMS (Oracle, PostgreSQL) — классические реляционные СУБД;
- Columnar DB (Vertica, ClickHouse) — колоночные хранилища для аналитики;
- NoSQL (MongoDB, Cassandra) — варианты для неструктурированных данных;
- Key-Value storage (SAP HANA, Redis, Apache Ignite) — хранилища для сверхбыстрой обработки.
- Apache NiFi — визуальный pipeline: удобно, понятно, без кода;
- Apache Airflow — более гибкий и мощный, работа с ним требует навыков;
- dbt — превращает SQL-запросы в управляемые модели, с тестами и Git'ом;
- Flink — для real-time потоков, например, с ASR/LLM.
- Metabase — удобно, понятно, умеет join'ы, даже без SQL;
- DataLens (Яндекс) — хорош при использовании ClickHouse;
- Grafana и Superset — подходят, когда надо работать с TSDBMS или когда используется Apache;
- Кастомная визуализация — подходят, если нужен свой веб-интерфейс (Django, FastAPI, React и т. д.).
- неизменность данных: информация сохраняется в исходном формате;
- временные метки: фиксируются даты поступления данных;
- контроль целостности: проверка корректности загрузки;
- минимальная обработка: только базовые преобразования;
- периодичность обновления: как правило, в режиме реального времени.
- стандартизация форматов;
- очистка данных; нормализация;
- создание связей между различными источниками;
- формирование агрегатов для ускорения аналитики.
- единая версия для всех пользователей;
- консистентность данных;
- масштабируемость;
- эффективность аналитики;
- поддержка принятия решений.
- Действуйте на опережение конкурентов! Внедрите DWH и получите преимущество в скорости принятия решений.
ETL-процессы
- базы данных разных форматов;
- файлы csv, xml, json;
- веб-сервисы и API;
- системы учета и CRM.
2. Преобразование (Transform). Данные очищаются, нормализуются и приводятся к единому формату. Что происходит:
- очистка от ошибок и выбросов;
- преобразование типов данных;
- объединение данных из разных источников;
- расчет новых показателей;
- проверка на соответствие бизнес-правилам.
3. Загрузка (Load). Данные помещаются в целевую систему. Это может быть:
- Data Warehouse;
- Data Lake;
- Operational Data Store;
- Data Mart.
- Представьте, что есть сеть магазинов. Каждый использует свою систему учета: складскую базу, CRM и финансовую систему. Программа извлекает данные о продажах во всех торговых точках и начинает обрабатывать их. Оказалось, что в одном магазине цены указаны в рублях, а в другом в долларах, в одном собраны данные о продажах за неделю, а в другом за сутки. Система приводит к единому формату даты, цены, данные о клиентах и др., а потом загружает всё в DWH. Компания получает единое хранилище для аналитики, может оценивать данные за разный период и структурировать информацию для отчетов.
Airflow и NiFi отличаются по требованиям к инфраструктуре: NiFi больше завязан на диски, Airflow — на CPU и RAM. Жесткие диски дешевле, это дает точку для оптимизации.
По визуализации Metabase выигрывает у Superset и Grafana, потому что позволяет делать join-операции через интерфейс, не зная SQL. В Metabase можно собрать нужные дашборды. Есть DataLens от Яндекса — особенно хорош, если используется ClickHouse.
Хороший вариант — dbt. Если перенести сюда написанный в SQL запрос, он будет лежать в Git, тестироваться и версионироваться. Это профессиональный подход, используемый в крупных компаниях. Присмотритесь к polyglot persistence: каждая база используется для своей цели, можно соблюдать баланс по теореме CAP. Мы используем PostgreSQL, Greenplum, ClickHouse и др.
Словом, для визуализации подходит простой и мощный Metabase, а если вы в экосистеме Яндекса, то выбирайте DataLens. Для разработки лучше использовать dbt + Python + различные инструменты для версионирования, тестирования и переиспользуемости запросов. Все зависит от ваших ресурсов и ситуации. А для хранилищ подойдет polyglot persistence. Я не акцентирую внимание на конкретной базе, потому что это вопрос задачи. Главное — понимать, для чего используется та или иная база
Павел Лукьянов
Заместитель CTO AGIMA
- Поиск активных клиентов
SELECT name, email
FROM customers
WHERE last_purchase_date > DATE_SUB(NOW(), INTERVAL 3 MONTH);
- Подсчет количества клиентов по городам
SELECT city, COUNT(*) as customer_count
FROM customers
GROUP BY city
ORDER BY customer_count DESC;
- Поиск незавершенных заказов
SELECT order_id, customer_name, total_amount
FROM orders
WHERE status = 'pending';
- Расчет общей суммы продаж за месяц
SELECT SUM(total_amount) as monthly_revenue
FROM orders
WHERE order_date BETWEEN '2025-05-01' AND '2025-05-31';
- Проверка наличия товара на складе
SELECT product_name, quantity
FROM inventory
WHERE quantity < 10;
- Обновление количества при поступлении товара
UPDATE inventory
SET quantity = quantity + 50
WHERE product_id = 101;
- Топ-5 продаваемых товаров
SELECT product_name, SUM(quantity) as total_sold
FROM sales
GROUP BY product_name
ORDER BY total_sold DESC
LIMIT 5;
- Средний чек по категориям
SELECT category, AVG(total_amount) as avg_check
FROM orders
GROUP BY category;
- Поиск сотрудников по должности
SELECT employee_id, name, department
FROM employees
WHERE position = 'manager';
- Расчет премий
UPDATE employees
SET salary = salary * 1.1
WHERE performance_rating > 4;
- Отчет по заказам клиентов
SELECT c.name, o.order_date, o.total_amount
FROM customers c
JOIN orders o ON c.id = o.customer_id
WHERE o.order_date >= '2025-01-01';
- Анализ эффективности рекламы
SELECT ad_campaign, COUNT(order_id) as orders_count,
SUM(total_amount) as revenue
FROM orders
JOIN ad_clicks ON orders.user_id = ad_clicks.user_id
GROUP BY ad_campaign;
- Поиск неудачных попыток входа
SELECT user_id, COUNT(*) as failed_attempts
FROM login_attempts
WHERE success = FALSE
GROUP BY user_id
HAVING COUNT(*) > 5;
- Логирование изменений
INSERT INTO audit_log (user_id, action, timestamp)
VALUES (123, 'deleted_order', NOW());
- Сравнение эффективности поисковой и баннерной рекламы
Запрос:
SELECT
platform,
COUNT(distinct click_id) as clicks,
COUNT(distinct order_id) as orders,
SUM(order_amount) as revenue,
SUM(ad_cost) as cost,
ROUND(SUM(order_amount) / SUM(ad_cost), 2) as ROI,
ROUND(SUM(ad_cost) / COUNT(distinct click_id), 2) as CPC,
ROUND(COUNT(distinct order_id) / COUNT(distinct click_id) * 100, 2) as conversion_rate
FROM ad_data
WHERE campaign_date BETWEEN '2025-04-01' AND '2025-04-30'
AND platform IN ('search', 'rsy')
GROUP BY platform
ORDER BY ROI DESC;
platform | clicks | orders | revenue | cost | ROI | CPC | conversion_rate
-------------------------------------------------------------------------
search | 2500 | 125 | 450000 | 150000 | 3.00 | 60.00 | 5.00%
rsy | 3000 | 80 | 320000 | 180000 | 1.78 | 60.00 | 2.67%
- Анализ эффективности рекламных креативов
SELECT
creative_id,
creative_name,
COUNT(distinct click_id) as clicks,
COUNT(distinct order_id) as orders,
SUM(order_amount) as revenue,
SUM(ad_cost) as cost,
ROUND(SUM(order_amount) / SUM(ad_cost), 2) as ROI,
ROUND(COUNT(distinct order_id) / COUNT(distinct click_id) * 100, 2) as conversion_rate
FROM ad_creatives
WHERE campaign_date BETWEEN '2025-04-01' AND '2025-04-30'
GROUP BY creative_id, creative_name
HAVING clicks > 100
ORDER BY conversion_rate DESC;
creative_id | creative_name | clicks | orders | revenue | cost | ROI | conversion_rate
--------------------------------------------------------------------------------------
101 | «Скидка 50%» | 1200 | 60 | 240000 | 80000 | 3.00 | 5.00%
103 | «Бесплатная доставка» | 1500 | 55 | 220000 | 90000 | 2.44 | 3.67%
105 | «Новый дизайн» | 1300 | 45 | 180000 | 85000 | 2.12 | 3.46%
- Управляйте данными профессионально! Доверьте внедрение DWH экспертам и обеспечьте надежность вашей бизнес-аналитики.
Модели данных
| Модель хранилища данных | Описание | Преимущества | Недостатки | Применение | Пример | Заголовок 7 | ||
|---|---|---|---|---|---|---|---|---|
| Звезда (Star Schema) | Самая простая и распространенная модель хранилища данных. Структура:
|
|
|
Оптимальна для:
Признаки применения:
|
-- Измерение: Курсы
CREATE TABLE dim_course (
course_id INT PRIMARY KEY,
course_name VARCHAR(100),
category VARCHAR(50),
difficulty_level VARCHAR(20)
);
-- Измерение: Студенты CREATE TABLE dim_student ( student_id INT PRIMARY KEY, name VARCHAR(100), country VARCHAR(50), registration_date DATE ); |
|||
| Снежинка (Snowflake Schema) | Расширение модели хранилища данных «Звезда» с дополнительной нормализацией измерений.
Структура:
|
|
|
Оптимальна для:
|
-- Нормализованные измерения CREATE TABLE dim_category ( category_id INT PRIMARY KEY, category_name VARCHAR(100) ); CREATE TABLE dim_product ( product_id INT PRIMARY KEY, product_name VARCHAR(100), category_id INT, FOREIGN KEY (category_id) REFERENCES dim_category(category_id) ); -- Факт-таблица CREATE TABLE fact_sales ( sale_id INT PRIMARY KEY, date_id INT, product_id INT, store_id INT, quantity INT, FOREIGN KEY (product_id) REFERENCES dim_product(product_id) ); |
|||
| Галактика (Galaxy Schema) | Множество связанных между собой моделей хранилища данных типа «Звезда». Структура:
|
|
|
Оптимальна для:
|
-- Общие измерения CREATE TABLE dim_date ( date_id INT PRIMARY KEY, year INT, quarter INT, month INT ); -- Факт-таблица 1: Продажи CREATE TABLE fact_sales ( sale_id INT PRIMARY KEY, date_id INT, product_id INT, revenue DECIMAL(10,2), FOREIGN KEY (date_id) REFERENCES dim_date(date_id) ); -- Факт-таблица 2: Закупки CREATE TABLE fact_purchases ( purchase_id INT PRIMARY KEY, date_id INT, supplier_id INT, cost DECIMAL(10,2), FOREIGN KEY (date_id) REFERENCES dim_date(date_id) ); |
|||
| Звезда с конкатенацией (Conformed Star Schema) | Модель хранилища данных, где измерения используются в нескольких схемах «Звезда». |
|
|
Оптимальна для:
|
-- Конформное измерение (общее для разных схем) CREATE TABLE dim_conformed_date ( date_id INT PRIMARY KEY, fiscal_year INT, week_number INT ); -- Факт-таблица 1 (Продажи) CREATE TABLE fact_sales ( sale_id INT PRIMARY KEY, conformed_date_id INT, product_id INT, FOREIGN KEY (conformed_date_id) REFERENCES dim_conformed_date(date_id) ); -- Факт-таблица 2 (Логистика) CREATE TABLE fact_shipping ( shipping_id INT PRIMARY KEY, conformed_date_id INT, destination_id INT, FOREIGN KEY (conformed_date_id) REFERENCES dim_conformed_date(date_id) ); |
|||
| Факт-константа (Fact Constellation) | Модель хранилища данных, где несколько факт-таблиц связаны общими измерениями. Структура:
|
|
|
Оптимальна для:
|
-- Общая факт-таблица CREATE TABLE fact_inventory ( inventory_id INT PRIMARY KEY, date_id INT, product_id INT, stock_quantity INT ); -- Связанная факт-таблица CREATE TABLE fact_sales ( sale_id INT PRIMARY KEY, date_id INT, product_id INT, sold_quantity INT, FOREIGN KEY (date_id) REFERENCES dim_date(date_id), FOREIGN KEY (product_id) REFERENCES dim_product(product_id) ); |
|||
| Data Vault | Модель хранилища данных, основанная на принципах хранения исторических данных и метаданных. Структура:
|
|
|
Оптимальна для:
|
-- Hub: Клиент CREATE TABLE hub_customer ( customer_bk VARCHAR(50) NOT NULL, record_source VARCHAR(50) NOT NULL, load_date TIMESTAMP NOT NULL, effective_date TIMESTAMP NOT NULL, PRIMARY KEY (customer_bk, record_source, load_date) ); -- Satellite: Атрибуты клиента CREATE TABLE sat_customer_details ( customer_bk VARCHAR(50) NOT NULL, record_source VARCHAR(50) NOT NULL, load_date TIMESTAMP NOT NULL, effective_date TIMESTAMP NOT NULL, name VARCHAR(100), address VARCHAR(200), phone VARCHAR(20), PRIMARY KEY (customer_bk, record_source, load_date) ); -- Link: Связь клиент-заказ CREATE TABLE link_customer_order ( customer_bk VARCHAR(50) NOT NULL, order_bk VARCHAR(50) NOT NULL, record_source VARCHAR(50) NOT NULL, load_date TIMESTAMP NOT NULL, effective_date TIMESTAMP NOT NULL, PRIMARY KEY (customer_bk, order_bk, record_source, load_date) ); |
- Lakehouse — гибридная модель Data Lake и Data Warehouse. Она подходит, если нужно анализировать большие данные, вы используете гибридную аналитику, машинное обучение и гибкие схемы хранения.
- Data Vault — модель для больших данных. Она подходит, когда речь идет о сложных системах, исторической аналитике, быстрой интеграции данных и высокой гибкости.
- Anchor Modeling — подход для сложных бизнес-процессов. Она подходит, когда вы работаете с проектами с быстро меняющимися требованиями и объемами данных, а также в средах, где важна гибкость.
- сложность бизнес-процессов;
- объем данных;
- требования к производительности;
- необходимость исторической аналитики;
- бюджет.
- чрезмерная нормализация в простых проектах и недостаточная в сложных;
- игнорирование требований к производительности;
- пренебрежение исторической аналитикой;
- отсутствие планов по масштабированию.
DWH vs Data Lake
| Характеристика | DWH | Data Lake | Заголовок 7 | |||||
|---|---|---|---|---|---|---|---|---|
| Структура данных | Строгая: это структурированное хранилище | Гибкая: данные хранятся в «сыром» виде | ||||||
| Скорость доступа | Высокая | Средняя | ||||||
| Аналитика | Развитая | Ограниченная | ||||||
| Сложность | Высокая | Средняя |
Технические требования
- Оптимизируйте принятие решений! Доверьте нам внедрение DWH и обеспечьте вашу команду надежным источником данных для стратегического планирования.
Роли в команде DWH (разработчик, аналитик)
- Высшее управление: руководитель, отвечающий за стратегическое управление данными в организации. Контролирует общее направление развития DWH и его использование. Есть CDO (Chief Data Officer), он отвечает за стратегию работы с данными, а есть руководитель DWH, он управляет всей командой.
- Архитекторы: разрабатывают общую концепцию и структуру хранилища, определяют подходы к интеграции данных, создают модели данных и схемы. Архитектор данных отвечает за структуру и целостность данных, ETL-архитектор за процессы извлечения, трансформации и загрузки данных, а BI-архитектор за системы бизнес-аналитики.
- Аналитики: собирают требования от бизнеса и формулируют технические требования. Определяют, какие данные и в каком виде нужны для решения бизнес-задач. Data Analyst работает с отчетами и анализом, Business Analyst взаимодействует с пользователями, а Data Quality Analyst отвечает за качество данных.
- Разработчики: создают и внедряют решения, обеспечивают надежность системы и техническую поддержку. DWH Developer — это непосредственно разработчик DWH, ETL Developer извлекает и преобразовывает данные, а Data Engineer поддерживает инфраструктуру.
- отчет за 5 лет генерируется за секунды, а не часы;
- при изменении формата данных из источника система не падает;
- аналитики понимают, где брать данные.