
Почему MVP — это важно
- зарегистрироваться;
- авторизоваться;
- увидеть объявления или подобрать специалиста;
- увидеть интеграцию с CRM;
- получить СМС или пуш и т. п.
Все основные шаги пользователя должны работать без багов. Особенно это касается вопроса оплаты. Любой баг в MVP — это боль, и их должно быть мало. Мы можем закрыть глаза на шероховатости процесса или ручные действия, но всё должно работать.
Какие сложности ждут команду
2. Почти всегда на старте теряются нюансы, и финальный скоуп расширяется.
Дело в том, что бизнес тоже развивается. Первоначальные идеи не всегда доживают до финала. Они развиваются, меняют приоритетность. Поэтому периодически возникают новые важные фичи, без которых нельзя запускать проект. Бывает и наоборот: фича, над которой команда билась неделю, вдруг становится не нужна.
3. Ошибки в реализации интеграций или объектной модели.
Важно понимать, что решения, которые вы принимаете на старте, будут жить с проектом долго. А изменить объектную модель сложно, так как у вас нет времени переписывать все сервисы, завязанные на нее. То же касается и архитектуры. Если вы ошиблись, скорее всего, придется жить с ней до завершения работ.
4. Подводные камни: сетевые инфраструктурные проблемы, БД нельзя использовать в соответствии с политикой компании, санкции, сервер слабее, чем должен быть, и т. п.
Тут может быть много неочевидных проблем. Например, на проекте в Казахстане мы с удивлением узнали, что у местного облачного провайдера нет Кубера. Нам пришлось вместе с ними тестировать и поднимать его. На это ушло 2 недели.
5. Из-за проблем выше часто страдает изначальная архитектура решений.
Архитектура, наверно, ключевой фактор в вашем проекте. Как вы построите систему, какие базы выберете, кто будет брокером, как будут общаться сервисы, какие будут модули. Ошибка на этом этапе многократно увеличивает количество часов в будущем на отладку и рефакторинг.
6. Любая ошибка в CORE очень много стоит.
Под CORE я понимаю модули или сервисы вашей системы. MDM, IDM и прочие сокращения, на основе которых вы строите обвязку сервисов для тех или иных нужд, либо какие-то ключевые пакеты, которые интегрируются во все сервисы системы.
Проблемы выше выглядят как проблемы менеджера, тимлида или архитектора. Но на этом этапе закладывается фундамент будущих проблем разработчика, поэтому понимать все эти обстоятельства важно.
Главные ошибки в MVP
Позже появилась вторая ошибка.
2. Не фиксируют скоуп работ.
В конце концов этот сервис расширился еще до выхода из MVP. В нем появилась возможность выбрать несколько вариантов фидбека. В каждом были свои варианты проблем в чекбоксе. В итоге мы сначала внедрили не самую важную фичу на MVP, а потом еще и расширили ее.
Кажется, что это недолго, но таких небольших задач много. Разработчик делает ее пару часов, тестировщик полчаса тестит ее, фронты поправят за час-полтора, тимлид провалидирует за то же время. И вот задача на 30 минут съела 4–6 часов.
А когда таких задач 30, вы потратите недели на то, что можно было бы сделать без нервов и горячки.
3. Неправильно выбирают архитектуру.
4. Слишком много или слишком мало времени тратят на ТЗ.
Бывает, что на простую функциональность пишут огромное ТЗ. Оно не очень поможет разработке, но съест много времени. Бывает и наоборот, когда на простую функциональность не дают ТЗ вовсе, хотя эта функциональность влияет на логику соседних сервисов. В итоге у нас получается несогласованность данных.
Из этого списка вы можете повлиять только на финальный скоуп и на его качество. Любой разработчик — это высокоинтеллектуальный юнит, и его мнение должно учитываться. Не стесняйтесь сказать тимлиду, что половину сервисов можно выкинуть из MVP, потому что они не важны. Или что сервис можно упростить, сделать хуже, но зато он будет работать. А после MVP можно вернуться к нему и отрефакторить.
Важно сделать качественно, важно сделать быстро. Остальное можно наверстать.
Пакеты и утилки
SSO и внутренние запросы
- В этой простой коммуникации одна проблема: нам нужно сделать внутренний сетевой запрос. Для его реализации нужно учесть 2 фактора:
- В этой простой коммуникации одна проблема: нам нужно сделать внутренний сетевой запрос. Для его реализации нужно учесть 2 фактора:
- обеспечение проксирования токенов,
- обеспечение коммуникации между сервисами,
- инкапсулирование адресов сервисов.
Теперь всё, что нам остается, создать новый клиент для общения с соседним сервисом, отнаследовавшись от S2S-клиента. В нем мы можем расширить логику. В итоге на создание унифицированного клиента для общения с любым сервисом требуется кратно меньше времени, правила общения остаются общими, снижается количество ошибок и упрощается работа с системой.
Логирование
- через какие сервисы прошел запрос,
- сколько было запросов в соседние сервисы,
- сколько они выполнялись и т. д.
Зачастую лог выглядит примерно так:
"Start integration. Time %%%%"
"Integration finished. Time %%%%"
"Integration error: %errors"
Если развернуть init в S2S-клиенте, то можно увидеть, что внутри S2S-клиента при инициализации создаются несколько клиентов: для общения с SSO и с сервисом. И это клиенты, унаследованные от BaseClient.
Затем всё это выкладывается в stdout и сохраняется в ELK, а в будущем этот лог используется в отладке и мониторинге.
Автотесты
- создание тестовой БД;
- установка миграций;
- корректная работа с транзакциями для откатки изменений каждого теста;
- клонирование БД для каждого воркера в случае запуска вместе с Xdist;
- различные удобные генераторы JWT-токенов с необходимыми пермишенами/ролями.
— тесты для проверки эндпоинтов с разной дебаг-информацией;
— тесты для эндпоинтов, которые всегда «падают» для проверки Sentry;
— тесты миграций лесенкой (идея подсмотрена у Александра Васина из Яндекс): накатываем одну миграцию, откатываем, накатываем 2 миграции, откатываем и т. д.;
— тесты для проверки корректности пермишенов у эндпоинтов.
- при запросе без jwt-токена;
- при запросе с некорректным форматом авторизационного хедера;
- при запросе с некорректным jwt-токеном (просрочен, несовпадающая подпись);
- при отсутствии прав доступа.
Асинхронные таски
- Dramatiq работает под Windows;
- для Dramatiq можно создавать Middleware;
- субъективно, но исходный код Dramatiq более понятный, чем у Celery;
- Dramatiq поддерживает перезагрузку при изменении кода.
Однако в процессе эксплуатации эти инструменты на нашем стеке показали себя не очень хорошо. В первую очередь оба эти инструмента нативно не поддерживают Asyncio. Это проблема, когда весь ваш код написан для работы в асинхронном режиме, а вам надо запустить это из синхронного кода.
Конечно, запустить его можно, но мы стали ловить разные трудноуловимые баги при работе с БД, редкие проблемы с транзакциями, фантомно закрывающиеся коннекты и т. д. К тому же оказалось, что логи нужного нам формата не очень легко прикрутить к Celery. Также непросто настроить корректный алертинг ошибок в Sentry согласно бизнес-логике. Бизнесовые эксепшены мы не хотим отправлять в Sentry, хотим только неожиданные от Python. Плюс конструкции для запуска асинхронного кода из синхронного выглядели ужасно.
Учитывая всё это, код наших тасок был монструозный, с разными костылями и трудно отлаживаемыми багами. Поэтому мы написали собственную реализацию продюсера-консьюмера на базе библиотеки Aiopika. Из кода исчезли костыли для запуска асинхронного кода, появилась возможность добавлять свои Middleware, но для воркера.
Поэтому мы перешли на другой подход: события сервисов-продюсеров стали просто бродкастами, то есть продюсеры перестали знать о своих консьюмерах, а сервисы-консьюмеры уже сами решали, надо ли им подписываться на эти события и сами, согласно бизнес-требованиям, стали проверять, надо ли обрабатывать это событие. Поскольку событие одно, а триггеров может быть сколько угодно, мы написали вдобавок простые классы-джобы такого вида:
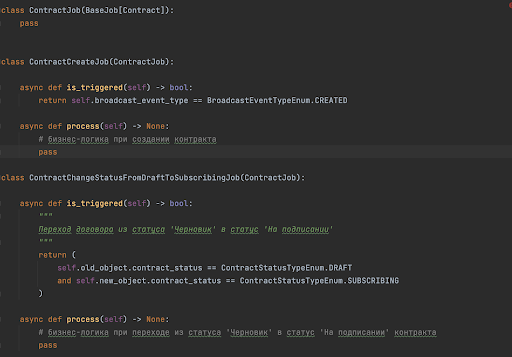
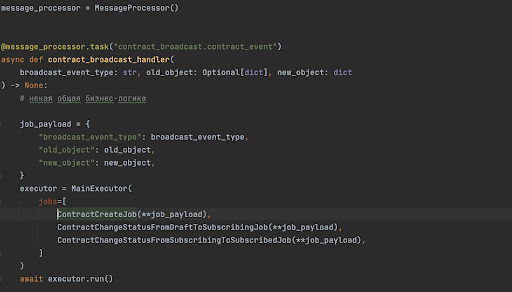
Рекомендации
С ними всегда очень много проблем, нужно постоянно сканировать код, чтобы не позволить появиться критическим уязвимостям.
2. Нагрузочное тестирование.
Проводить его нужно обязательно. Сложно заранее понять, какую нагрузку выдержит ваша система. Зачастую проблемы возникают после нагрузки выше определенного RPS.
3. S3-хранилища.
В монолитных архитектурах вы всегда можете управлять файлами в отдельном пакете. Чаще всего проверяется объем файла, допустимое расширение, проверка на исполняемость файла, ограничение на количество загрузок файлов. Также нам необходимо проверять, не протух ли файл, вовремя чистить хранилище и т. д.
В микросервисах этим пакетом является отдельный микросервис. А значит, вам придется агрегировать всю логику обработки файлов в нем. Это несет накладные расходы. Нам нужно знать, от какого сервиса файл был загружен, какие у него метаданные. Файл приходится грузить напрямую в сервис S3. То есть микросервис, по бизнес-логике которого требуется загрузить файл (фотографии, docx, excel и т. п.), ничего про файл не знает, у него есть только метаданные.
В микросервисах этим пакетом является отдельный микросервис. А значит, вам придется агрегировать всю логику обработки файлов в нем. Это несет накладные расходы. Нам нужно знать, от какого сервиса файл был загружен, какие у него метаданные. Файл приходится грузить напрямую в сервис S3. То есть микросервис, по бизнес-логике которого требуется загрузить файл (фотографии, docx, excel и т. п.), ничего про файл не знает, у него есть только метаданные.
4. Обязательно используйте авгоненерируемую документацию.
В FastAPI она идет из коробки. В Django есть Django-yasg. Готовая автодока экономит огромное количество времени фронтам и мобилкам.
5. Не пренебрегайте типизацией.
Отличный способ убедится, что вы правильно используете пакеты и классы и не совершаете глупостей.
6. Пишите автотесты
Там, где много коммуникаций, без них не обойтись. Для вас это будет защита от лишних багов и прекрасный инструмент для разработки.
7. Просите помощи у коллег, если зависли на каком-то вопросе.
Это не стыдно, это нужно делать. Так вы быстрее завершите задачу, не сорвете сроки, не будете заниматься самобичеванием. Брейншторм — отличная практика, пользуйтесь ей.
8. Настройте Sentry.
Это простой и мощный инструмент, который легко поднимается в Standalone-режиме. Sentry легко настроить в любом фреймворке. Внедрить его в проект — не более 30 минут.
9. Фиксируйте версии библиотек.
В наших проектах по умолчанию используется Poetry. В нем и в других Dependency-менеджерах есть возможность указать минимальную версию библиотек. Но тут маленький нюанс. Обычно указывается только минимальная версия библиотеки, которая вам нужна. Но это плохо. Когда библиотек много, особенно популярных, выше шанс поймать конфликт пакетов.